A few months ago while having some issues updating Openelec on my RPi I decided to blitz the SD card and go FULL Openelec with a fresh install of version 6. However this had some problems, namely that it no longer functioned as a file server – or rather it could, but the lack of options to configure ports, passwords and other configs generally make file hosting through Openelec a huge security risk, and even if you hack your way around the read-only filesystem, it just gets overwritten when it next updates.
I decided to buy another Raspberry Pi. With the model 3 out now, model 2’s became a lot cheaper. I picked up one here for £25. I decided early on it was just going to be a fileserver, so after it was set up I wasn’t going to need a keyboard/Mouse/HDMI plugged in. Just power, hard drive and network – with the aim to control everything via VNC and SSH.
The Pi arrived, and I installed Raspbian on the SD card and plugged it in, I’d gone for a direct install of Raspbian so didn’t get the setup I had seen before when using NOOBS, however you can trigger this yourself from the terminal. So open up the terminal and type
sudo raspi-config
Then you can go through the setup process. After I had set that stuff up the way I wanted I had the following to-do list:
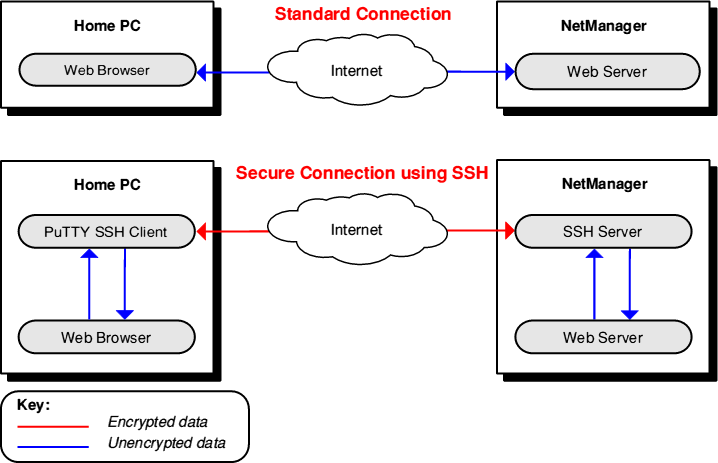
- Configure SSH to be more secure.
- Mount my external HDD locally.
- Install samba and configure it to share the hard drive over the network
- Install VNC and set it to launch on startup as a virtual desktop
Configure SSH to be more secure
SSH can be brute forced, that shouldn’t be a surprise. Raspbian by default will give you a default username and password. If you haven’t changed it already, change your password, you can do this by opening up the terminal and entering the command passwd
I also find that you can avoid most bot attacks if you simply change the default port that SSH runs on, so I recommend opening up the config file located at /etc/ssh/sshd_config and changing the value for Port, the default is 22 – change it to something memorable, then either restart the Pi or use sudo service sshd restart
You should now be able to access your raspberry pi from any given SSH client with ssh pi@192.168.0.X -p 1234 Where X is the IP address and 1234 is the secret port you set up.
Mount my external HDD locally
Linux can pretty much mount anything (phrasing) it will prefer stuff formatted for EXT3/4 but can also read from NTFS, FAT and HFS file systems. When you plug in a hard drive it will by default mount itself in the folder /media/. I wanted to mount my hard drive in another location just for the sake of ease. To do this you need to create a folder as a mount point and then configure the fstab to mount the device in that location.
So first of all, figure out what your device is called, to do this plug the device in, open up the terminal and use the command sudo blkid if your device has a name (My device is called “JOES-SLAB”) then you should be able to pick it out of the list of results.
~$ sudo blkid
/dev/sda1: LABEL="JOES-SLAB" UUID="82AA5C66AA5C58AD" TYPE="ntfs" PARTUUID="7dd7743f-01"
So I can see that my external NTFS HDD is mounted on /dev/sda1. Copy and paste the UUID as you will need that later. At this point you should unmount the drive, leave it plugged in but use the command
umount /dev/sda1
Where /dev/sda1 is the mount point of your device. If it successfully unmounts then you need to open up and edit /etc/fstab This file will be root protected so you’ll need to open with elevated permissions.
The fstab is a table which gives the system information on how to mount certain devices. It may already have information in it, this is fine, just got to the bottom of the file and start a new row. The fstab takes 6 fields
- Device
- Mount Point
- Filesystem
- Options
- Dump
- Pass
So, using the UUID you recorded earlier you can add your device to the fstab. An example of mine is below, then an explantion of what each field means.
UUID=82AA5C66AA5C58AD /home/pi/Documents ntfs-3g uid=1000,gid=1000,umask=022 0 0
Device: UUID=82AA5C66AA5C58AD – Each storage device will have a UUID, this lets the operating system know how to mount this device
Mount Point: /home/pi/Documents – When I open this folder the contents of the hard drive will be displayed. This file path needs to exist in order for this to work so you need to create this directory if its not already there.
Filesystem: ntfs-3g – my hard drive uses NTFS, the 3g options is an external package which helps with the read/write stuff. In all fairness I’m not all that clued up, this is just what works. If your hard drive is FAT or HFS(+) have a google as to what you need to put in here.
Options: uid=1000,gid=1000,umask=022 – NTFS hard drives don’t let you change read/write/execute permissions after they’re mounted so you need to set them up here. This setup will give you ownership and set the hard drive permissions to 755, so only user pi has the ability to write to the HDD but others can read and execute.
Dump & Pass: 0 – No idea, that’s just what you need to put
Save the fstab, then in the terminal run sudo mount -a this will reload everything in the fstab. If everything went to plan, you should find the contents of your HDD listed under /home/pi/Documents (or whatever mount point you specified)
Install samba and configure it to share the hard drive over the network
Samba is a package in unix/linux that allows for file and printer sharing across a local area network, I used this mainly so I could map the hard drive on my raspberry pi on other devices, like my windows laptop and PC.
Samba is probably already installed, but run sudo apt-get install samba just in case. Once installed you can find the main configuration file at /etc/samba/smb.conf open that up with elevated permissions. The file will already contain a lot of configurations, some of them are contained within a parent configuration which is denoted by the [] brackets. For instance at the top level is [global].
Under [homes] I added my own custom configuration, as before I’ll show the code then explain each option.
[Public Documents]
comment = Public Documents
path = /home/pi/Documents
guest ok = no
browseable = yes
read only = no
create mask = 0755
directory mask = 0755
[Public Documents] – this lets samba know that its reading a new configuration section, this is also how the folder will appear when viewing from another device, for example if I logged into my pi from my PC I would see \\raspberrypi\Public Documents
Comment: A description of the drive, usually I give the same value as above
path – this is the local path to the location you wish to share across the network (it matches our HDD mount point)
guest ok – No, I want people to log in before they access my hard drive! If you’re not bothered you can set this to ‘yes’
browseable – Yes, I want to be able to browse the drive
read only – No, I want to be able to write to the drive
create/directory mask – The permissions applied to the network drive
Save and quit. Now since I specified that guests were not okay, the final thing to do is to set up your user as a valid login. To do this, in the console use the command smbpasswd pi. This will allow you to set a password with samba for your login, you are allowed to set the same password as when you were configuring SSH, which means when accessing the drive remotely you can login with your usual username and password. You can always specify a different user than “pi” but I’m not sure how that would conflict with the fstab permissions on the drive. Also remember that in future if you change your password to update both.
Restart samba with the command sudo /etc/init.d/samba restart after which you should be able to access your hard drive from another device across the network. On windows I can map the drive using the map network drive wizard, and connecting using different credentials, where I enter the Pi’s username and password. Sometimes you may need to specify the domain of the user account, as windows will sometimes try to log you in as a local user rather than a remote one (i.e “WindowsPc\pi” rather than “raspberrypi\pi”) So just be sure to specify the domain name of your pi, if you don’t know what this is use the command hostname on your pi and it should tell you. As in the screenshots below.

If all has gone according to plan, your remote drive should show under the z:\ on your windows device (or phone, or tablet)


Can I access my files from outside my local network?
Yes you can actually, not through Samba though. If you’ve configured SSH properly you should be able to port forward the secret port you specified to your device externally, for this you’ll need to give your device a static IP on your network and set up the port forward rule – these are usually done through your router/gateway.
Once you have port forwarding setup you can actually use SFTP to access your files. SFTP is like FTP but uses an SSH connection to secure and tunnel the connection so you don’t need to install anything new. With any file transfer program that can handle SFTP you can connect using sftp pi@X.X.X.X -p 1234 again where X.X.X.X is your public external IP address and 1234 is the secret SSH port you set up.
Linux has SFTP support built in, for windows devices and android I recommend
Install VNC and set it to launch on startup as a virtual desktop
The final step is to install and setup VNC, VNC is a server application which will allow you to connect to a device and view the desktop and optionally use the keyboard and mouse as a means of remote desktop control. It’s old tech but I prefer that as it can be used with almost any device, and you can still secure it (although the method we’re going to use only uses 8 character passwords for some god awful reason)
In my experience Raspbian has 2 main VNC packages, Tight-VNC and Vino-VNC. Vino works by allowing the VNC server to assume direct control of XSession in progress, if you had a monitor connected you would see the mouse cursor moving, opening files and typing. Tight-VNC creates virtual XSessions which are identical to your normal desktop, but you don’t need a monitor and even if you did have one plugged in, the session you control through VNC would not be the same.
I opted for TightVNC in this case, as I did not need my RPi to be plugged into a monitor, keyboard or mouse after it was setup. Install TightVNC by opening the terminal and typing sudo apt-get install tightvncserver once installed you can run the application, on first run you will be asked to set up a password. As a mentioned earlier you can only set up an 8 character password, you can enter more text – so if you can only remember a longer password you can still type it in, the program will just truncate it. Run TightVNC with the command vncserver You will be asked to enter a password and then verify, then you’ll be offered to setup a view-only password. This you can give out to people so they can view your desktop but have no control.
Once the server is running you will likely see a message like New 'X' desktop is running on raspberrypi:1. This means your VNC server is now running on virtual desktop 1. The virtual desktop ports correspond to actual TCP ports too. By default VNC servers start at port 5900, so when TightVNC says it’s running on raspberrypi:1 what it means is “Locally I’m running on desktop 1, externally I’m running on port 5901”. TightVNC cannot run on port :0 as this is the REAL desktop environment, so when you just run vnc without any extra parameters it will default to run on port 5901. If you have a VNC client on another machine on your local are network you can connect to your VNC server with X.X.X.X:5901, and entering the password you created in the setup. If you want to run on a different virtual desktop port, just remember that any other devices on your network will need to access it via the TCP port 5900 + the value you set as the virtual desktop, I’ll explain more on that as we go.
End the VNC server session with the command vncserver -kill :1. This will terminate any VNC servers running on virtual desktop 1. Since we want our VNC server to start on system load, and we want to customize the setup the easiest thing to do is figure out what options we want to run the server with, and then automatically run that setup on system startup. You have a few options but I only want to set resolution and colour depth. So, create your new script and enter the following. I’ll explain what it does after
vncserver :101 -geometry 1366x768 -depth 24
:101 this is the virtual desktop, this directly affects the TCP port which your VNC server runs on, so my server would run on port 6001 (starting at 5900 + 101), again changing the port is a good way to avoid most bot attacks.
-depth 24 Sets the colour depth, if you have a particularly slow connection you can
-geometry 1366×768 this sets the resolution of your virtual desktop. It can be as big or small as you like, I set it to this because it will fit onto the smallest device in my house without much scaling, but you can set to anything you see fit.
Now you have a command which will run the VNC server, on the port and resolution you want, you just need to make this command run automatically. I found that sometimes the server booted up before the desktop environment. You’ve got free reign here to chose your own method, but I found the one below works best – originally from this post
Open up a new text file and enter the following text
[Unit]
Description=TightVNC remote desktop server
After=sshd.service
[Service]
Type=dbus
ExecStart=/usr/bin/tightvncserver :101 -geometry 1366x768 -depth 24
User=pi
Type=forking
[Install]
WantedBy=multi-user.target
Save it under the directory /etc/systemd/system/tightvncserver.service The only thing you may need to alter is the line starting ExecStart, where you can see our command to start the server. You may notice that vncserver has been replaced by /usr/bin/tightvncserver don’t worry about this too much as its essentially the same command, you’re just providing an absolute path to the binaries to execute it, you can also alter the user running the service if you wish.
Once the file is in place you need to make it owned by the root user and then install it as a system service. Open terminal and run the following commands.
#Configure the script to run at startup
sudo chown root:root /etc/systemd/system/tightvncserver.service
sudo chmod 755 /etc/systemd/system/tightvncserver.service
sudo systemctl enable tightvncserver.service
If you want to test that your script is running, run the following command and you should see either the vnc startup message, or an error if its already running.
#To test the script is working
sudo systemctl start tightvncserver.service
To test it’s working, restart your device and see if you can connect to the VNC Server.
Once it’s working the way you want, you can disconnect your keyboard, mouse and monitor as your Raspberry Pi is now running as a virtual environment.
To connect to your VNC server I recommend the following clients (sorry I don’t have any Mac devices)
Can I access my VNC server outside of my network?
Yes, you can, but you shouldn’t, having your VNC exposed makes you vulnerable to a few attacks, and once they break your VNC server they can actually control your device without needing your password so it’s not wise to simply port forward your VNC port. I recommend using SSH tunnelling, which the android app I suggested will support. I discussed this in more depth in one of my previous articles here. It depends on how secure you want things to be, but yes, there’s no reason why you can’t remote control your device over the internet.
A strange bug with VNC having no taskbar
When I was connecting to my desktop session, I found that all I saw was my desktop wallpaper. This was because the Xsession desktop environment was not actually being loaded in the virtual desktop. You home directory contains a hidden folder called /home/pi/.config/lxpanel/ in this folder you have the potential to have a copy of the LXPanel config files, you just need to copy them from the system directory.
cp -r /etc/xdg/lxpanel/profile/LXDE /home/pi/.config/lxpanel
cp -r /etc/xdg/lxpanel/profile/LXDE-pi /home/pi/.config/lxpanel #This command might fail if you're on an older RPi model
This should fix the LXPanel issues on your virtual desktop and you should be able to use VNC to control your virtual desktop now.
your virtual desktop now.









Recent Comments